 Jemand zu Hause?
Jemand zu Hause?
| 8 Einträge, 1 Seite |
![[Homepage]](/battie/theme/default/homepage.gif)
1
2
3
4
5
6
$<*digits*>
Contains the subpattern from the corresponding set of capturing
parentheses from the last pattern match, not counting patterns
matched in nested blocks that have been exited already.
(Mnemonic: like \digits.) These variables are all read-only and
dynamically scoped to the current BLOCK.
1
2
3
4
5
6
7
8
9
10
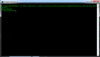
#!/usr/bin/perl
use warnings;
use strict;
my $string = "111222333";
$string =~ m/(\d{3})(\d{3})(\d{3})/;
print "$1\n$2\n$3\n";

1
2
3
4
5
6
7
8
9
10
use HTML::Parser ();
my $p = HTML::Parser->new(
api_version => 3,
start_h => [\&start, "tagname, attr"],
marked_sections => 1,
);
$p->parse_file("datei.html");
sub start {
print "$_[1]->{src}" if $_[0] eq "img"
}
 Wie frage ich & perlintro brian's Leitfaden für jedes Perl-Problem
Wie frage ich & perlintro brian's Leitfaden für jedes Perl-Problem| 8 Einträge, 1 Seite |
 Blog
Blog Einstellungen
Einstellungen![[Powered by Battie]](/battie/img/powered.png)
